后端服务代码分层是个老话题,但最近几年没什么人聊了,因为吹牛的去聊虚拟化、高可用、k8s,骗钱的去聊ai了。也导致一些新人基础代码没怎么写过,就开始疯狂学习这些高大上的东西,不过我一直觉得,先把基础的搞好了,再提高大上也不迟。而且这些年来我见过了各种分层,但似乎没有哪一种是能够真正解决了高复用,低耦合,又不麻烦的,大部分是都是会偏向于理论化,实际用在项目上总会放人懵逼,这一块代码到底要放哪呢?怎么放更合理呢?以至于每次有新模块时,我都会纠结怎么设计,因为老觉得之前做的还有可改进的地方;经过好多年的思考和迭代,希望能总结出一些东西来
首先,MVC对于当下的服务分层有些太简单了,或者说最早设计出来时就太简单了,只是一个偏指导性的,而且当下前端的解耦,让View层更不变的可有可无,让我感觉更有指导方向的是阿里牵头出过的《java开发手册》,虽然我用过c,php,golang,甚至matlab,C#,js,但唯独没有正经用过java,不过java本身是一个工程向很重,架构方法论发展非常好的语言,哪怕不用java,它也会在设计模式、工程架构上对人有很高的启示和示范
再提问题,为什么要分层?我个人理解就是要解决复用和解耦。复用我觉得体现在初建阶段,比如读表,需要有一层专门负责所有表的读写,其它层只关心这层暴露的接口,不关心怎么写表,怎么读;解耦体现在维护期,比如表改了,不能所有读表的接口都要改,都要关心你这个表具体怎么变的,如果仅仅是字段扩长度,字段结构改了,那表层自己cover就可以,上层不需要感知。这两点说起来简单,但搞起来却能有千变万化的玩法,分的太细,写起来麻烦,分的太粗,维护起来又糊涂。总之我理解一个好的分层设计应该是当你有一块代码逻辑时,你会明确的知道要把它放在哪,同时又不需要关心别的层面怎么做的,只需要关心下层提供了什么
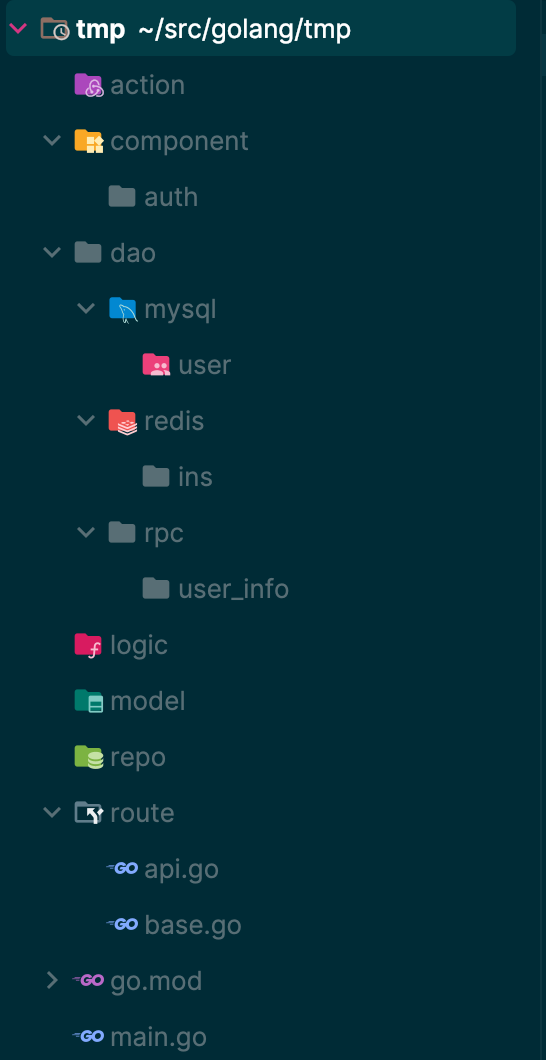
dao层:
所谓的数据接口层,和数据库对接的,直接操作表的,但我理解,除了数据库操作外,缓存、rpc等直接和本模块交互的都可以放在dao层,所以dao层又可以拆为dao/redis、dao/mysql、dao/rpc、dao/local-cahce,而这里的暴露的数据结构应该就是原始的表结构、rpc返回值、redis实际存储等
repository层:
repo层我理解是dao层的组合或带有通用业务属性的方法集合,组合的情况比如,先读redis,读不到的话读db,这种读多种数据源才能获取到数据的就可以放到这里;把dao层的原始返回结构转化为业务逻辑里通用的model数据结构,如坐标、用户信息等,1是比如我获取的用户信息rpc里只有一部分是业务关注的,那可以转化裁剪一些非关注字段,2是比如表的数据是一个复杂结构,如json格式,业务使用时肯定不能每次都转换,那可以通过repo层来转化json字符串为业务格式。如果用repo封装过dao层,那就可以使用repo层来获取、处理数据,不需要走dao层。而repo层一般情况下复杂结构的输入输出都应该是model层的数据结构
component层:
顾名思义是一些组件,而且这些组件应该是带有业务属性的,比如权限验证、业务相关的状态机、任务组件等,而且我理解这里的组件是尽量不与repo层和dao层打交道的纯业务逻辑操作组件,具体数据应该是从调用层传进来的,这样可以保证不会出现循环引用,这层和util包的区别应该在于util不包含任何业务属性,都是些类型转换、日期计算之类的通用功能
model层:
这里都是一些业务类的数据结构和数据结构自身的成员函数,和其他人使用习惯不同,我理解这层不包含任何model来源和构造的逻辑,具体model数据怎么组织是其它使用model层的决定,比如可以来源于web请求参数,可以来自repo组织,而logic里对于复杂的数据结构都应该用model来组织,model应该是贯穿整个业务逻辑的
logic层:
logic层应该在于repo层之上,是所有接口的业务逻辑所在处,它也应该拆为common和具体接口logic,common里放着通用业务逻辑,具体接口logic是每个接口对应到一个logic方法,同时也可以拆分出多组子方法
action层:
主要是要处理请求参数,校验参数,处理和结构化返回值等,这个就比较简单了,处理完参数后直接调用对应接口的logic就可以
router层:
这个就是url和method对应action的关系了